
"Méthodologie de documentation orientée devops"
Le point de départ
L'article précédent sur la mise à jour Woodpecker s'était conclu sur un constat: le problème venait principalement de la documentation. Si elle existe, elle n'est pas assez organisée, structurée.
J'ai décidé de prendre le problème à la racine. Comment documenter correctement une infrastructure ?
La méthode des 5 familles
En cherchant sur le sujet, je suis tombé sur le travail de Stéphane Robert, DevOps Engineer, qui a synthétisé une classification en 5 familles. L'idée centrale : chaque document répond à une seule question.
- Cartographie — qu'est-ce qui existe ? (inventaires, listes de services)
- Architecture — comment ça fonctionne ? (diagrammes, flux de données)
- Procédures — comment agir ? (runbooks, checklists)
- Référentiel — qui, quels accès, quelles conventions ?
- Historique — pourquoi ce choix ? (ADR, postmortems)
Ce qui m'a surtout aidé, c'est de nommer les anti-patterns que je pratiquais. La doc éparpillée dans chaque "projet". Une documentation mélangée: cartographie, architecture, runbooks. Difficulté pour effectuer des recherches.
Incident → diagnostic → hotfix rapide → ça refonctionne → on passe à autre chose.
Surtout sur un homelab sur un problème non prévu à la base. Même si la volonté de documenter est présente, cette dernière est souvent très brouillon et demande plusieurs itérations pour être améliorée.
Ici, utiliser le bon outil peut aider: blog.stephane-robert.info - Choisir ses outils de documentation
Mon outil: générateur de pdf
J'avais déjà Flowboard, un viewer PHP pour documenter mes projets en HTML/CSS, avec export PDF via mPDF : page de garde, table des matières, pagination. Ça fonctionnait bien. Mais c'était limité : PHP uniquement, pas de Markdown, pas de support Docker propre, et un mode d'édition (contenteditable) trop fragile pour une vraie base de connaissances.
Construire quelque chose de plus solide
J'ai commencé par extraire la génération PDF de Flowboard en microservice autonome : phpaper.
Une API REST simple en PHP: elle reçoit du HTML, elle retourne un PDF.
Consommable depuis n'importe quel langage.
Ensuite, j'ai reconstruit le viewer en Go avec goWebFlow : bunkops. Le changement principal par rapport à Flowboard : support Markdown natif, Monaco Editor pour éditer directement dans le navigateur (le même éditeur que VS Code), et les diagrammes Mermaid. Le tout containérisé en Docker.
Ici, j'apprends petit à petit à penser "container". Je me rends compte de la flexibilité offerte et que je dois consolider mes connaissances théoriques.
Où j'en suis
J'ai maintenant deux choses que je n'avais pas avant : une méthode pour organiser la documentation infrastructure, et un outil adapté à mon usage.
Le chantier en cours, migration de l'existant et des habitudes à prendre.
Petit aperçu de l'outil
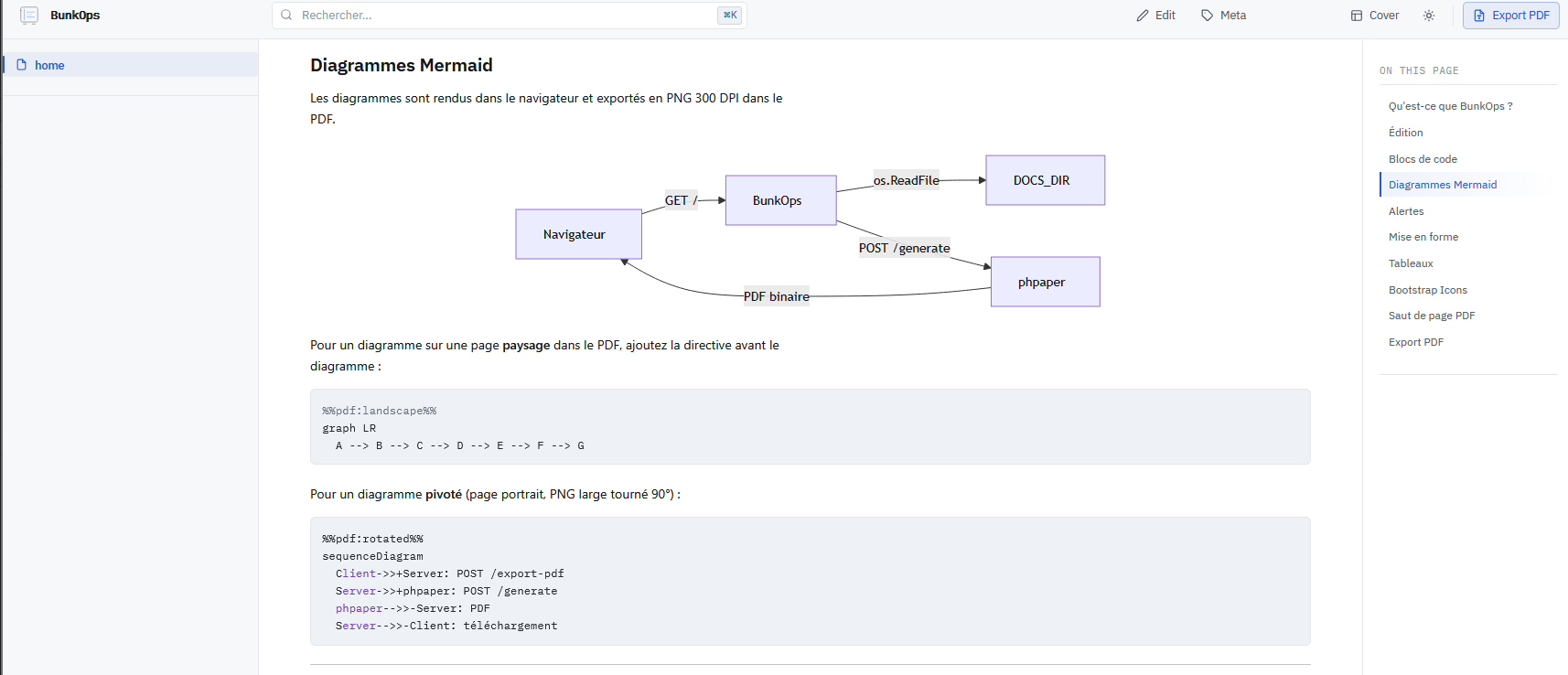
Bunkops et Phpaper ne sont pas encore publiés, usage perso pour l'instant.